Parallel processing
Staff: Prof C. B. Allen
High fidelity flow simulation can be extremely expensive. For example, rotor simulations require the vortical wake, and its effect on the following blades, to be captured accurately. Hence, the development of an efficient flow-solver is essential.
Prof Allen has developed a multiblock upwind flow-solver applicable to fixed-wing and rotor flows. The code can be run as unsteady, using an efficient implicit scheme and, and includes mesh motion and deformation schemes for unsteady flows with moving surfaces. The code has been made more efficient by adding multigrid acceleration and has been parallelised using MPI.
Parallelisation involves splitting the computational domain into smaller domains, and sending each one to separate processors. Hence, all sub-domain are solved simultaneously, resulting in faster solution. The speed-up obtained normally depends on the number of processors available, the size of the initial mesh, and the domain decomposition scheme developed.
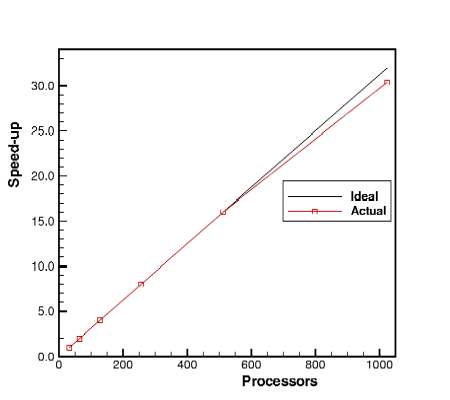 Prof Allen is a member of the UK Applied Aerodynamics Consortium, for supercomputing in aerodynamics, which has been awarded a significant amount of CPU time on the national supercomputing resource HPCx. As part of this research, the performance of his code was evaluated by the Terascaling Team at Daresbury Laboratories. Below is the scaling achieved by the code for a 20 million cell rotor calculation. Simulations were run on 32, 64, 128, 256, 512, and 1024 processors, and a factor of 1 was used on 32 CPUs. Hence, a speed-up of over 970 was achieved on 1024 CPUs, and the code has been awarded a Gold Star for this scaling performance.
Prof Allen is a member of the UK Applied Aerodynamics Consortium, for supercomputing in aerodynamics, which has been awarded a significant amount of CPU time on the national supercomputing resource HPCx. As part of this research, the performance of his code was evaluated by the Terascaling Team at Daresbury Laboratories. Below is the scaling achieved by the code for a 20 million cell rotor calculation. Simulations were run on 32, 64, 128, 256, 512, and 1024 processors, and a factor of 1 was used on 32 CPUs. Hence, a speed-up of over 970 was achieved on 1024 CPUs, and the code has been awarded a Gold Star for this scaling performance.